
By Des Nnochiri
Log files in Linux often contain information that can assist in tracking down the cause of issues hampering system or network performance. If you have multiple servers or levels of IT architecture, the number of logs you generate can soon become overwhelming. In this article, we’ll be looking at some ways to ease the burden of managing your Linux logs.
Centralizing Linux Logs
One of the best practices for managing Linux logs is to aggregate or centralize them in a single location. This is particularly useful if your IT infrastructure involves multiple servers, many layers of storage architecture, or sites in geographically-dispersed locations. The same wisdom applies for any organization that uses a mixture of on-premises servers and cloud services.
Centralizing your logs in a single location makes it much easier to search through them for any useful information they might contain. Instead of trying to guess which server has the particular Linux file you want, you can simply refer to your central repository of logging data to search for relevant events. This makes it easier and quicker to troubleshoot problems or resolve production issues. In many cases, engineers may be able to resolve issues without directly accessing systems.
Most Linux systems use an on-board syslog daemon to centralize logs. Syslog is a service which collects log files from services and applications running on a host. It can write these logs to file or forward them on to another server via the syslog protocol. There are a number of variants including Rsyslog, a lightweight daemon installed on most common Linux distributions, and syslog-n, the second most popular syslog daemon for Linux.
Large management solutions for Linux logging use centralization as a key feature, since it enables them to analyze, parse, and index logs before storing them at a central hub. Centralization allows for logs to be backed up in a separate location, protecting them against accidental loss or if your on-site servers go down.
Besides reducing the overall amount of disk space required for keeping log files, having them stored at a single location also saves on computing resources, which might otherwise have to be wasted on complex searches using SSH or inefficient grep commands.
Managing Log Rotation
Log files on Linux systems automatically roll over. The system maintains only a fixed number of the rolled-over logs. Rotation may occur quite frequently, and when it occurs, the current log is given a slightly different file name, and a new log file is established.
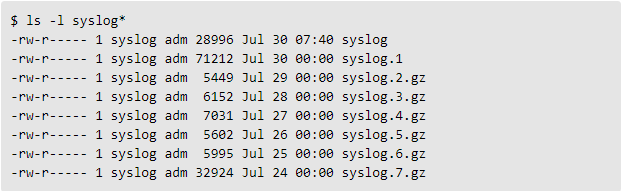
The example illustrated below shows rotation for the syslog file, which typically stores your normal system messages:
(Image Source NetworkWorld )
)
Older syslog files roll over at midnight each night and are kept for a week, after which the oldest is deleted. So in the example above, the syslog.7.gz file will be deleted from the system, and syslog.6.gz will be renamed syslog.7.gz. The rest of the log files will follow the same pattern until syslog becomes syslog.1 and a new syslog file is created. In general, you’ll never see more than eight of these log files at a time, giving you just over a week to review any data they collect.
The number of files a Linux system maintains for any particular log file depends on the log file itself. For some, the number of files included may be as many as 13. Older files—both for syslog and dpkg—are typically compressed or g-zipped to save space. You can use gunzip to expand any older files that you’re particularly interested in.
Note that log files may be rotated based on age and size, so you should keep this in mind when you examine them. You can look at files like /etc/rsyslog.conf and /etc/logrotate.conf for details on how to configure rotation on your system.
Using Log Files
Knowing how to pull information from log files can be very beneficial when you want to get a sense of how well your Linux system is working or if you need to track down a particular problem. To do this effectively, you’ll need to get a general idea of what kind of information is stored in each file and what that data can tell you about your system’s performance and any problems it might have encountered.
The screenshot below gives some typical examples:

(Image Source NetworkWorld)
There are also Linux commands that you can run to extract information from your log files. For example, to view a list of system reboots, you can use a command like this:

Image Source NetworkWorld)
Using Advanced Log Managers
Though you can write scripts to make it easier to find relevant information in your log files, there are sophisticated tools available for log file analysis. Some advanced log managers can correlate information from multiple sources to give a fuller picture of what’s happening on your network. Others can provide real-time monitoring. Among the top commercial tools are SolarWinds Log & Event Manager and PRTG Network Monitor.
There are also free log management tools if you need to handle your Linux logging on a budget. For instance, Logwatch is a program that scans system logs for lines that might indicate certain kinds of activity, and the Logcheck utility is a system log analyzer and reporter.