
By Des Nnochiri
Keeping redundant copies of essential files and programs can assist in recovery when system glitches or other incidents occur. However, duplicate files also hold the potential to confuse matters and introduce errors. It’s possible to have too much of a good thing, so keeping track of these duplicates is always a good idea.
Why Files Sometimes Multiply
If you’re a music, video, or graphics enthusiast, you’ll understand how easy it can be for files with similar names or similar content to pile up on your storage drives. What might surprise you is that this kind of download or file-saving activity isn’t the biggest cause of file replication on most systems.
Operating systems and application software are actually the biggest culprits. These programs often create duplicate files for entirely legitimate purposes.
Some programs are designed with built-in mechanisms to protect them from the malfunctioning of other, related software. One way of doing this is for an application to install its own local copy of a shared library or support files. This prevents the software from losing access to essential files or code if another program that uses the same library is uninstalled or becomes hopelessly corrupted.
Operating systems typically offer users the option of rolling back their installation to a previous version if the current set-up becomes damaged or corrupted by a virus attack or some other circumstance. This requires entire sets of OS files to be held in a designated portion of your hard drive, many of which will be exact duplicates of files on the currently active operating system.
Similarly, when some applications update themselves, they’ll save copies of any files that have been changed in case the upgrade goes wrong and the previous installation needs to be restored.
When More Means Less
Besides their potential to consume large quantities of valuable storage space, duplicate files can sometimes create problems affecting usability or operational matters.
If, for example, the information making up a duplicate file set becomes corrupted, applications depending on this data for their functionality may exhibit erratic or even destructive behaviors. Duplicate files may slow down or complicate system-wide operations, such as file indexing or database sorts and searches.
The Issue of Hard and Symbolic Links
In a Linux environment, the issue of duplicate files may be even more pronounced. That’s because two or more entities on a Linux drive can have different names yet still be recognized by the system as identical versions of the same file.
Files sharing the same disk space in a Linux installation will share the same inode, which is the data structure that stores all the information about a file except its name and its content. Two or more files with a common inode may have different names and file system locations, yet they’ll still share the same content, ownership, permissions, and other characteristics.
Files like these are known as hard links. They operate in contrast to symbolic links, which point to other files by containing their names. In her analysis of this subject for NetworkWorld , Sandra Henry-Stocker points out that symbolic links are easy to identify in a file listing by the “l” in the first position and the -> symbol that refers to the file being referenced:
, Sandra Henry-Stocker points out that symbolic links are easy to identify in a file listing by the “l” in the first position and the -> symbol that refers to the file being referenced:
$ ls -l my*
-rw-r–r– 4 shs shs 228 Apr 12 19:37 myfile
lrwxrwxrwx 1 shs shs 6 Apr 15 11:18 myref -> myfile
-rw-r–r– 4 shs shs 228 Apr 12 19:37 mytwin
Finding Duplicate Files in Linux
To identify the hard links in a single directory, you can list the files using the ls -i command, and sort them by inode number. The inode numbers will appear in the first column of this type of output.

(Image source: NetworkWorld)
Rather than scanning reams of output for identical node numbers, it’s possible to find out if one particular file is hard-linked to another. In this case, you should use the -samefile option of the find command. The starting location that you provide to the find command will dictate how much of the file system is scanned for matches. In the example below, the search takes place in the current directory and its subdirectories.

(Image source: NetworkWorld)
To find duplicate files and drill down to more detail on their characteristics, you can use the find command’s -ls option:

(Image source: NetworkWorld)
The first column of output displays the inode number. It then lists the file permissions, links, owner, file size, date information, and the names of any files that refer to the same disk content.
To locate all instances of hard links in a single directory, you can run a script like this:
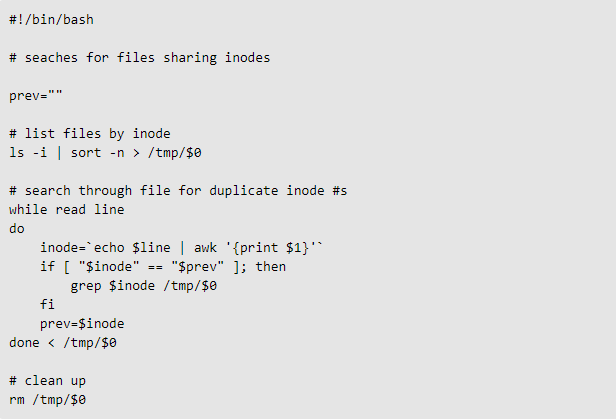
(Image source: NetworkWorld)
Note that using this method to scan for Linux duplicate files which contain the same content but don’t share inodes (i.e., simple file copies) takes considerably more time and effort.