Linux systems provide a simple command known as split, which enables you to break large files up into smaller pieces. In this guide, we’ll be discussing the syntax, and giving some practical examples of its use.
Why It’s Sometimes Necessary To Split Linux Files
Some online storage sites put a maximum limit on the size of each upload. So if you have a large file whose size exceeds the cap, the Linux split command provides an alternative to zipping or file compression.
Using split, you can break large files up into several smaller pieces, upload them individually, then reassemble them once all the information is in one place. This technique also applies if you need to transmit a document via email, and the mailing system puts a size limitation on file attachments.
Split Command Naming Conventions And Syntax
By default, the split command uses a simple naming scheme for file fragments. Each file portion in a sequence is designated as xaa, xab, xac, etc. With a large enough file for example, the set of pieces might go all the way from xaa to xzz.
Also by default, split runs silently, without any feedback to the user. If you’d like the split command to echo what it’s doing, you’ll need to use the –verbose option. This command line parameter will cause the split command to display each of the file fragments as they are being created. Here’s an example:
$ split –-verbose bigfile
creating file ‘xaa’
creating file ‘xab’
creating file ‘xac’
You can add a prefix to the filename for greater clarity or if, for example, you have a number of files to subject to the splitting process. So, to name all the pieces of your original file bigfile.xaa, bigfile.xab, etc., you could add a prefix to the end of your split command, like this:
$ split –-verbose bigfile bigfile.
creating file ‘bigfile.aa’
creating file ‘bigfile.ab’
creating file ‘bigfile.ac’
By convention, a dot is added to the end of the prefix shown in the above command, to associate each fragment with the original bigfile. If the dot had been left out, the split command would instead have produced a set of file fragments with run-on names like bigfilexaa, bigfilexab, and so on.
File Handling With Split
The Linux split command creates the fragments without removing your original file. It’s possible to specify the size of the file fragments, by adding the -b modifier to the command line syntax.
The following example would split bigfile into 100 megabyte pieces:
$ split -b100M bigfile
You can specify file sizes in kilobytes, megabytes, gigabytes, terabytes, petabytes, and all denominations up to the known maximum (yottabytes?). All specifications have to use the appropriate letter from K, M, G, T, P, E, Z and Y.
Files may also be split on the basis of a certain number of lines in the document, rather than bytes. For this, you’ll need to use the -l (lines) option. In the example below, each file will have 1,000 lines, with the possible exception of the last one which may have fewer lines.
$ split –verbose -l1000 logfile log.
creating file ‘log.aa’
creating file ‘log.ab’
creating file ‘log.ac’
creating file ‘log.ad’
creating file ‘log.ae’
creating file ‘log.af’
creating file ‘log.ag’
creating file ‘log.ah’
creating file ‘log.ai’
creating file ‘log.aj’
Reassembling Split Files
If you need to reassemble your file from fragments on a remote site, you can use a cat command like one of these:
$ cat x?? > original.file
$ cat log.?? > original.file
With the commands we’ve covered so far, splitting and reassembling may be accomplished for both binary and text files. For splitting and reassembly, you can use the diff command to verify that the originally split file and the reassembled product are the same.
In this example, we use split to break the zip binary file into 50 kilobyte pieces, use cat to reassemble them, and then compare the reassembled and original files:
$ split –verbose -b50K zip zip.
creating file ‘zip.aa’
creating file ‘zip.ab’
creating file ‘zip.ac’
creating file ‘zip.ad’
creating file ‘zip.ae’
$ cat zip.a? > zip.new
$ diff zip zip.new
$ <== no output = no difference
Splitting Files On The Basis Of Context
To split files based on context, you can use the csplit command. The basic syntax reads:
csplit [OPTION]… FILE PATTERN…
The parts are defined by context lines, with the output pieces of FILE separated by PATTERN(s) to files ‘xx00’, ‘xx01’, etc. The output byte counts of each piece conform to standard output.
If for example we have a text file named list.txt with contents as follows:
- Apples
- Bananas
- Oranges
- Pineapples
- Guava
We can split this file into two parts (with the second part starting from 3rd line) using the csplit command in this manner:
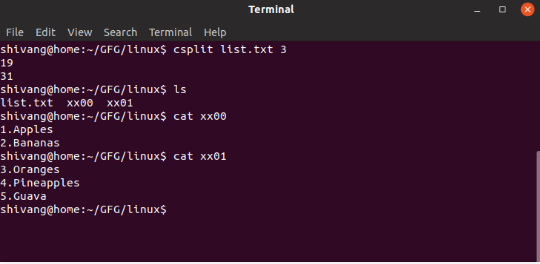
(Image source: GeeksforGeeks.com )
)
A Word Of Caution
If you use the Linux split command often with the default naming convention, you can easily end up overwriting some file chunks with others. And if you have file fragments left over from some earlier split, your file storage system may be playing host to more pieces than you were expecting.